На сейчас вырисовался уже график, можно сделать для себя пару заметок.
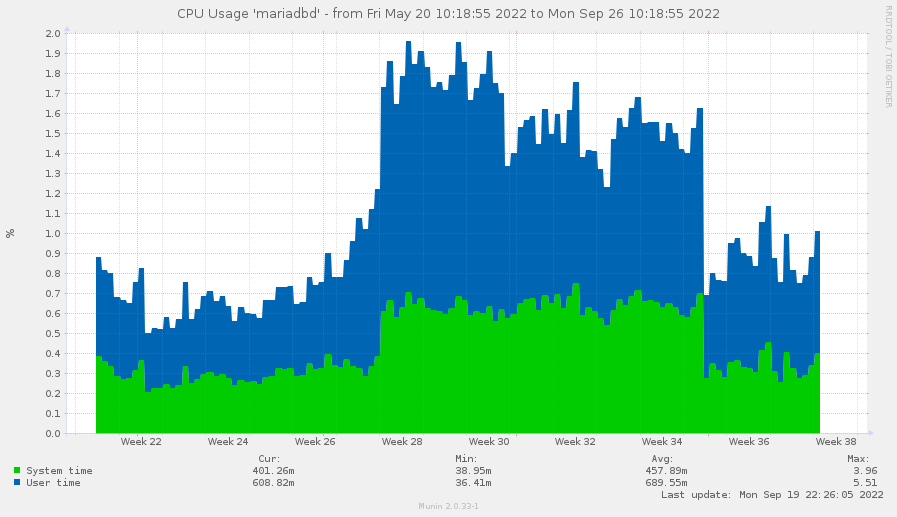
Начало ступеньки – вроде как 10-е июля. Согласно коммитам (которые я мог делать с задержкой), единственное изменение, которое могло поднять нагрузку – это создание нескольких подключений. Конечно, можно вытащить старую версию транспорта из репозитория и протестировать “до” и “после” снова, но это не сильно удобно, поэтому лучше просто рассуждать логически. Коммиты я делал не на каждый чих, но это было довольно-таки значительное изменение. Остальные или не должны влиять, или напротив, должны были снизить нагрузку. Так что остается только “пул подключений”.
А окончание ступеньки – 30 августа – я хорошо помню – это замена кода в isFeedNameRegistered() с SQL-запроса на обход массива. В итоге такая оптимизация сократила нагрузку на базу до значений до введения пула подключений.
Из того, что потенциально можно пробовать оптимизировать – работа isSent() – там реально много запросов прилетает: каждая активная лента * число записей. Даже если 2 десятка лент по 2 десятка записей в ленте – вот уже 400 запросов на каждое обновление.
Но на пока нагрузка от этого находится на уровне десятых долей и находится на уровне погрешности измерения, а тащить лишние данные в память не хочется.
Буду наблюдать.
Update: поставил размер архива в 30 дней, по прошествию этого времени сделал скриншот с Munin’а. Число запросов к базе в итоге выросло примерно в 4-5 раз.
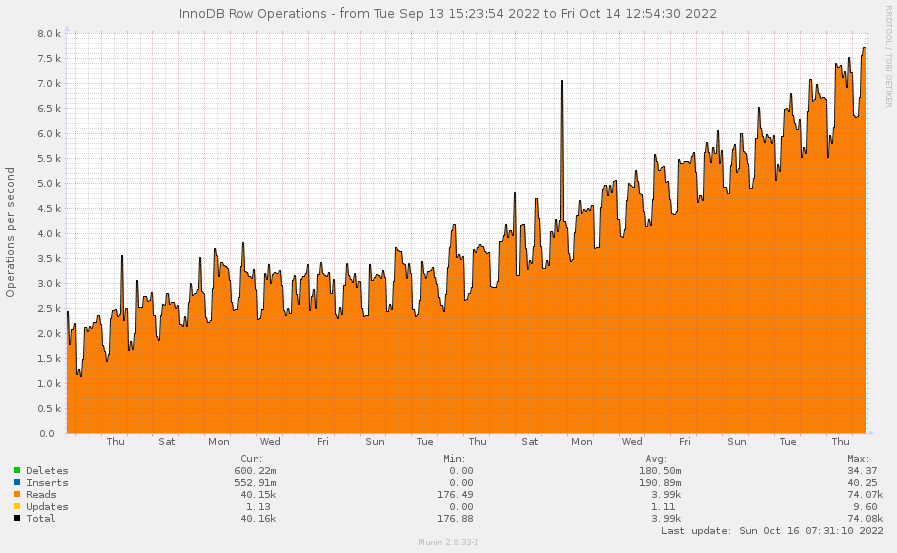
Однако нагрузка на процессор заметно не поменялась. В любом случае стоит заняться оптимизацией базы.